Unleashing the Power of Intelligent Retrieval: A Deep Dive into Vector Databases, Embeddings, and RAG
Discover how vector databases, embeddings, and Retrieval-Augmented Generation (RAG) transform static AI models into dynamic, knowledge-aware systems. Learn the underlying architecture, practical workflows, and Python code examples to integrate RAG into your own AI projects.
Vladan Djurkovic
11/7/20253 min read
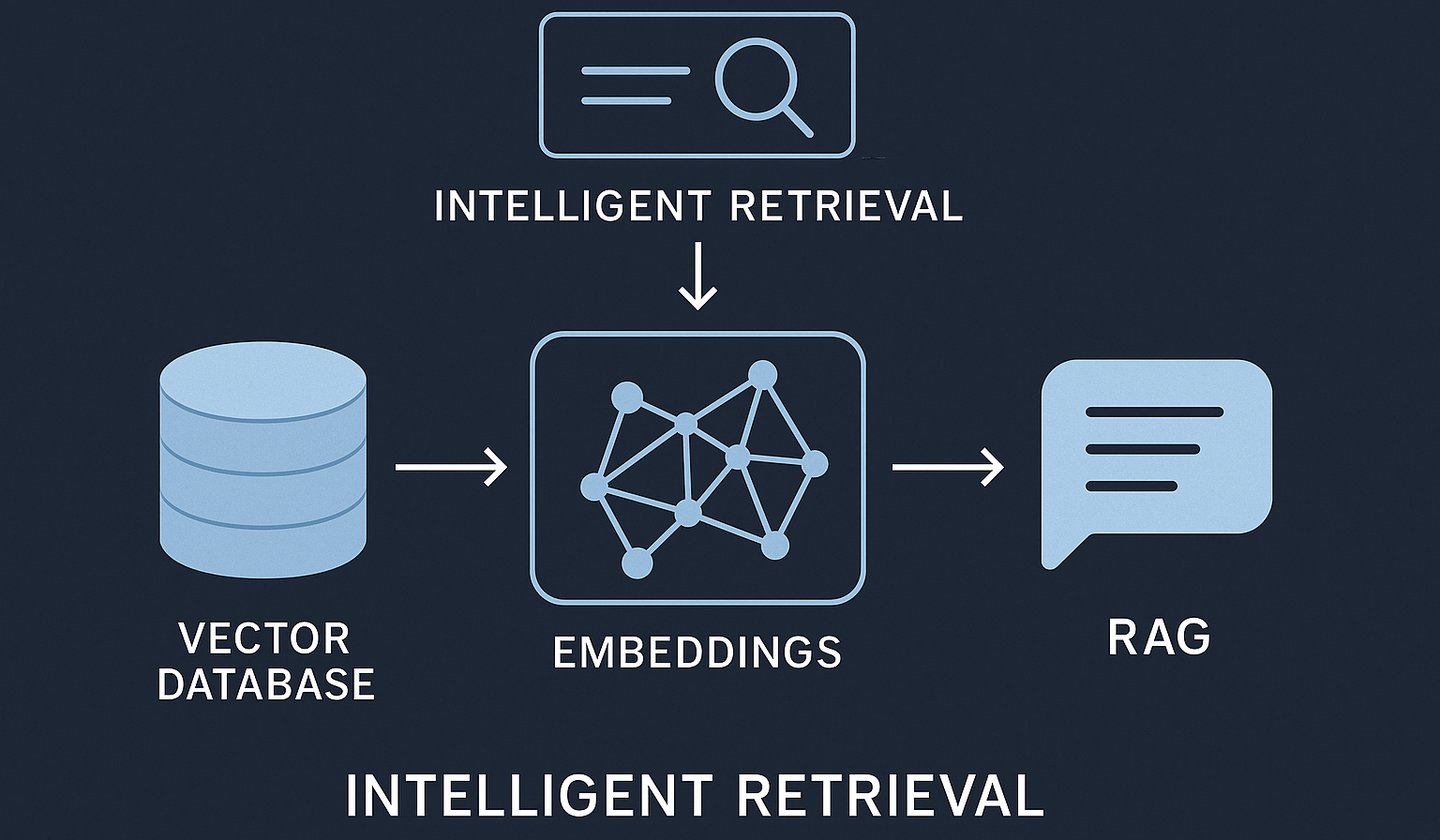
Artificial Intelligence (AI) is evolving rapidly, but even the most advanced large language models (LLMs) like GPT, Claude, or Gemini share one fundamental limitation: their knowledge is static. Once trained, they can’t automatically access new information unless retrained or connected to an external source.
This is where vector databases, embedding models, and retrieval-augmented generation (RAG) come into play. Together, they create a dynamic AI ecosystem capable of retrieving and reasoning over live, organization-specific data.
This post dives into the technical foundations of these technologies, explains how they work, and provides example code for implementation.
Knowledge Enhancement Approaches: In-Context Learning vs. Direct Retrieval
AI systems today can enhance knowledge using two complementary methods: in-context learning and direct retrieval.
In-Context Learning (ICL)
ICL allows models to process new information temporarily during runtime, without retraining their internal parameters. For example, when you paste a document into a chat, the model uses that text to respond accurately, but the information is forgotten after the session ends.
Direct Retrieval
Direct retrieval (also called direct technology) connects the model to external data sources, like vector databases, allowing it to access live, factual information in real time.
This is the foundation of RAG systems, where LLMs blend stored knowledge with retrieved, current data, enhancing accuracy, context awareness, and reliability.
The Role of Embedding Models: Turning Meaning into Numbers
Before an AI can “search by meaning,” text or data must be transformed into embeddings, numerical representations that capture semantic relationships. An embedding model maps text into vectors, lists of floating-point numbers in a high-dimensional space. The closer two vectors are, the more similar their meanings.
Even though “Apple fruit” and “Banana” have no shared words, their embeddings are close because they’re semantically related.
Popular Embedding Models
OpenAI: text-embedding-3-large – excellent for general semantic accuracy
SentenceTransformers (BERT-based) – ideal for open-source or offline use
Cohere and Hugging Face models – scalable, customizable embedding pipelines
Example: Generating Embeddings with OpenAI
This vector can then be stored in a vector database for later semantic retrieval.
Vector Databases: Searching by Meaning, Not Keywords
A vector database is a specialized system optimized for storing and searching high-dimensional vectors.
Unlike relational databases (like PostgreSQL or MySQL), which rely on exact matches, vector databases support semantic search, retrieving information based on meaning rather than keywords.
How It Works
A query is converted into an embedding vector.
The database measures cosine similarity or Euclidean distance between the query vector and stored vectors.
The most similar entries (closest vectors) are retrieved.
Common Vector Databases
FAISS (Facebook AI Similarity Search): Fast, open-source library for vector search.
Pinecone: Fully managed vector database for scalable, low-latency retrieval.
Weaviate: Open-source, schema-based, hybrid (text + vector) search.
ChromaDB: Lightweight and Python-native — perfect for prototyping.
Example: Semantic Search with FAISS
From PDFs to Vectors: The Document Upload Pipeline
A typical RAG workflow for document ingestion includes these steps:
Document Ingestion:
Parse PDFs or text files and split them into smaller “chunks” (e.g., paragraphs). Tools like LangChain, LlamaIndex, or Unstructured.io handle this efficiently.Embedding Creation:
Pass each chunk through an embedding model to generate vectors.Storage:
Save vectors with metadata (e.g., source title, author, timestamp) in a vector database.Query Time:
When a user asks a question:Convert it into a vector.
Search for the most similar chunks.
Retrieve and rank the results.
Feed the top results into an LLM to produce a grounded answer.
This pipeline enables the fusion of retrieval and generation, the foundation of intelligent AI systems.
Retrieval-Augmented Generation (RAG): The Engine Behind Smart AI
Retrieval-Augmented Generation (RAG) bridges the gap between static model knowledge and dynamic external data.
How It Works
When a user asks: “What are the benefits of vector databases for enterprise search?”
RAG performs the following steps:
Embeds the question into a vector.
Searches the vector database for related document chunks.
Injects those results into the LLM’s context window.
The LLM generates a contextually accurate and fact-based response.
Example: LangChain RAG Workflow
Direct Retrieval vs. Fine-Tuning: Why RAG Wins
Fine-tuning a model requires retraining it with new data, a time-consuming, expensive process. It’s best used for style adaptation or domain-specific tone.
RAG, however, enables instant access to fresh data:
No retraining required
Updates knowledge in real time
Scales effortlessly across
document repositories
Benefits of RAG
⚡ Speed: Update knowledge in minutes, not weeks
✅ Accuracy: Retrieve contextually relevant data
📈 Scalability: Handle massive document collections efficiently
Practical Applications of RAG Systems
Conclusion: The Future of Knowledge-Aware AI
Vector databases, embeddings, and RAG are redefining how machines understand and interact with information.
Instead of being static systems, AI agents are evolving into knowledge-aware entities capable of real-time reasoning. With tools like FAISS, Chroma, LangChain, and Pinecone, developers can now build intelligent retrieval systems that combine the best of search and generation.
The future of AI isn’t just about bigger models, it’s about smarter, connected, and contextually aware systems that learn from the world in real time.